(Disclaimer: Possibly one of my longest post ever, you may want to scroll to the bottom and only look at the pictures.)
So, what’s new in SD since last week?
Fetching everything
From http://bugs.freedesktop.org/, it was possible to download all the bugs I reported there (that means 2…), but trying to download those reported by Julien led to a crash without any trace. Dichotomy FTW, I came up with a bunch of bugs which would lead to the same result, which confirmed that the amount of bugs processed at once wasn’t the issue.
Playing around with strace, it appeared that exchanges with the remote
server were apparently fine, so an issue on the client-side SOAP
machinery got suspected. So let’s enable tracing:
use SOAP::Lite +trace => 'all';
Tada! The issue was indeed local: malformed XML got received, leading
to a die call issued from the XML-RPC layer. Thankfully, one can set
up a fault handler, which I used to display the range of bug IDs which
triggered that bug, so that people can look into it and determine what
to add to the blacklist until the underlying issue’s been investigated
(presumably, bugzilla’s at fault).
Speeding things up
With that blacklisting of buggy bugs, one can then try to move to other queries, dealing with more bugs. Some examples follow:
reporter=kibi@d.o
product=xorg&component=Driver/VMWare
product=xorg&component=Driver/nouveau
product=xorg&component=Server/general
product=xorg&component=Driver/intel
Moving from 2 bugs to 10-100 bugs (Julien’s or VMWare’s) was OK. But
then moving to several hundreds of bugs (Driver/nouveau = 500+ bugs) led to
noticeable performance issues. Not to mention what happened when one
reaches several thousands of bugs (Driver/intel = 2500+ bugs). Indeed, even
with network exchanges cached into a local file, processing data was
taking up to several dozens of minutes.
I knew about Perl’s -d:DProf, which helps figuring out where time is
spent, but was pointed to -d:NYTProf (and its accompanying tool,
nytprofhtml). Some hotspots got noticed:
- There’s a huge pile of stuff relying on UUIDs heavily, and a cache is going to be introduced to avoid later calls once a value’s been computed once. That’s going to benefit all replica types, not just bugzilla.
- I didn’t care much about date/time at the beginning, but that
turned out to be a very bad idea: since the format returned by
bugzilla wasn’t matching a “well-known” format, time was spent in
the
DateTime::Format::Naturalfallback, leading to a big performance penalty. Fixed with a trivial regular expression.
Things got better, but not good enough. There are several
Prophet (the engine under the hood) backends,
so one can play with:
PROPHET_REPLICA_TYPE=sqlite # the default for SD
PROPHET_REPLICA_TYPE=prophet
Switching to prophet was a big win, but still not good
enough. Indeed, many tiny files are written, and most of the time is
spent in I/O. Although I’m nothing like a performance guru, I guessed
that running on an average laptop, with ext3 and its default commit
interval of 5 seconds might not be helping, so I gave a quick try to
-o remount,commit=60, and that seemed to help.
Even though there are probably other tricks to find in that area
(which hopefully won’t require root privileges…), there’s already a
patch which landed in prophet’s master branch, replacing
File::Spec->catfile with an optimized version: that function alone
was eating 10% of runtime…
In the sqlite case, disabling the auto-commit feature helped
reducing the I/O load, but a proper patch is still lacking for now
(running into locked database issues, or into missing tables after
having created them isn’t fun, so I postponed debugging that).
Since performance issues looked like they could be solved eventually, I switched back to implementing missing features.
Handling more than comments
Currently 3 types of stuff are currently fetched from the bugzilla server:
- Bug status: plenty of properties.
- Bug comments: comments that are linked to bugs.
- Bug history: changes that impacted bugs.
(Yes, that means that attachments are totally ignored for now.)
Until now, only bug comments were considered. The first comment was used to determine a pseudo-title (using its first line), the reporter, and the creation date. This approach was chosen to try and get a basic sync working quickly, so as to get:
- A list of bugs matching the query.
- All comments for each of these bugs.
Now, the algorithm is the following: from the bug status, determine a
set of properties of interest; then walk the history backwards, and
update the properties incrementally until the (presumed) “initial
state” is reached. Then create the ticket using this “initial
state”. Adding the incremental property changes to that initial
ticket makes it possible to represent the bug’s life as a list of
Prophet::ChangeSet objects.
That’s where the fun begins, since properties in the bug status may
not match properties in the bug history, so one needs to establish
property correspondence. Also, some properties can be multivalued for
added fun. I believe that’s where most of the time is going to be
spent while developing a new replica type in SD: once one knows how to
get a hand on needed info on the remote server, the main question is
what to do with it. For now, I decided to ignore many fields to make
it possible to do a “big” sync like Server/general, property support
will be improved later on.
Screenshots
Instead of pasting lengthy terminal excerpt, let’s use some screenshots instead (sorry, I’m not sure how to present such things in an accessible way, suggestions welcome).
Cloning Julien’s bugs, listing all open tickets, listing all
tickets, searching using a regular expression:
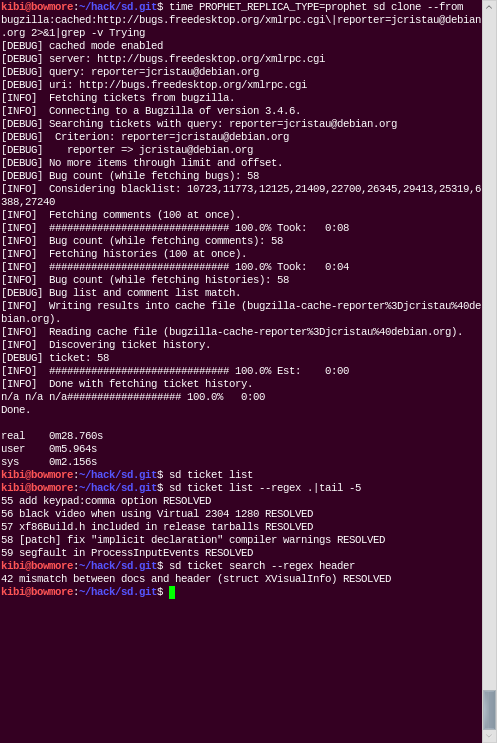
Displaying bug 42 (that’s the local ID):
Now, let’s start the embedded web server through sd server --port
1234 and point the browser there.
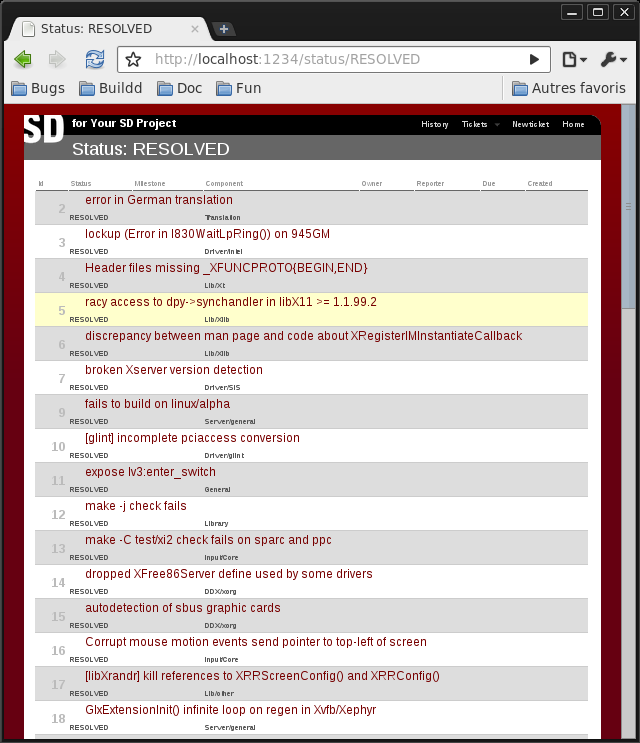
List of RESOLVED bugs:
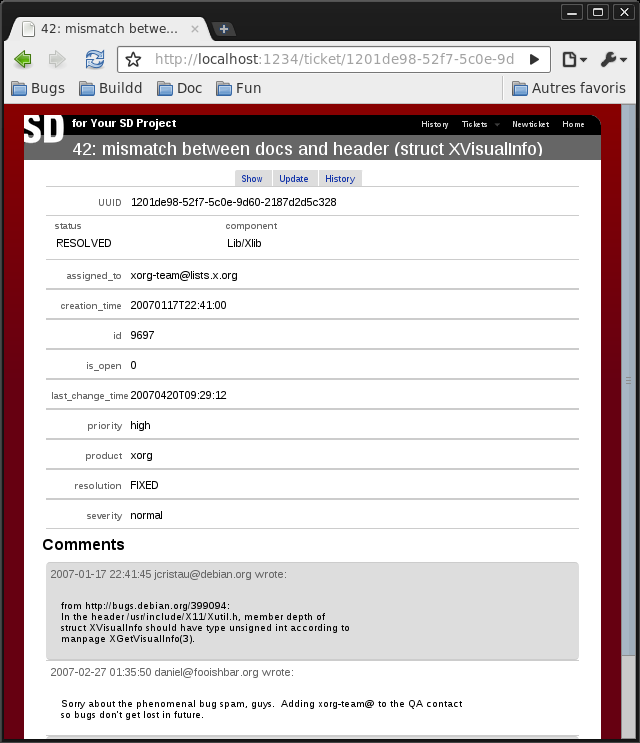
Status and comments for bug 42:
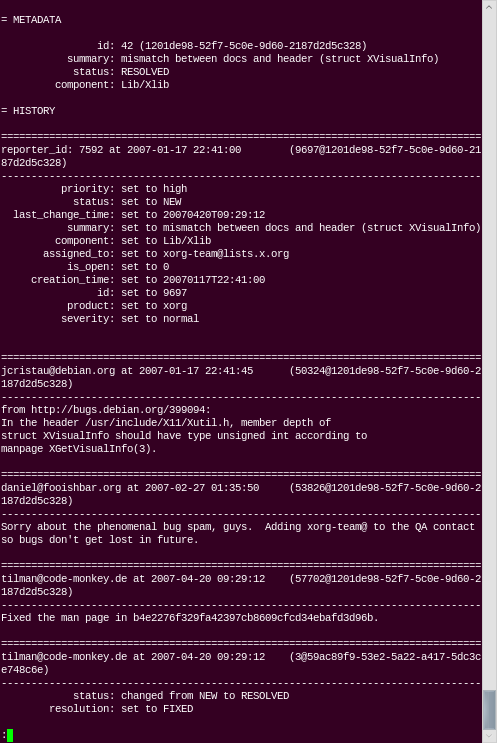
History for bug 42:
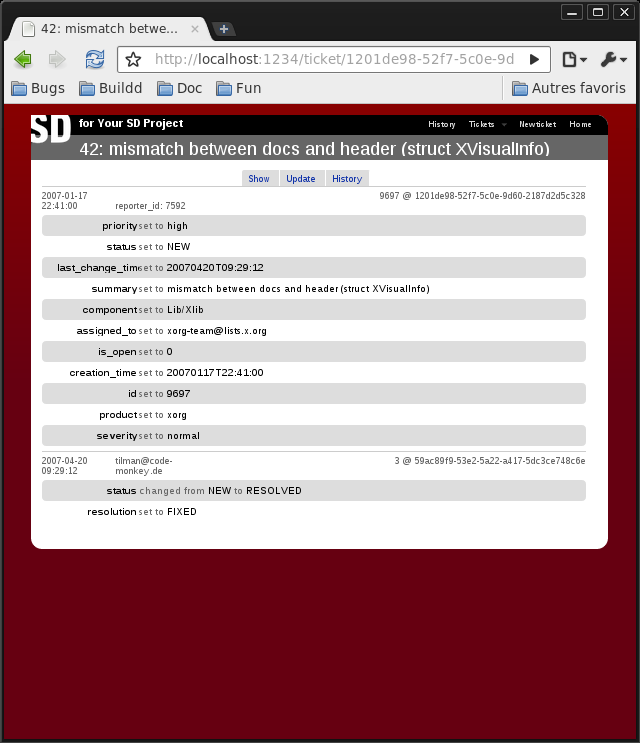
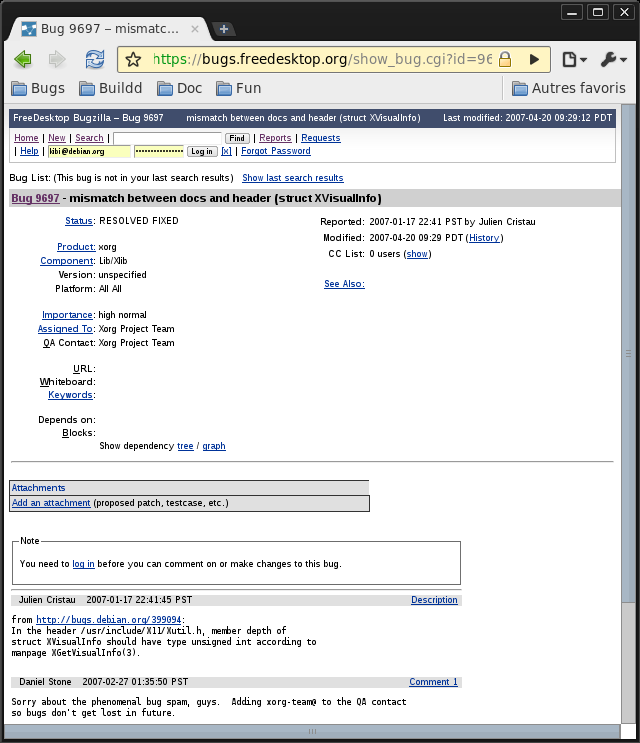
Compared to the original bugzilla page:
Next time
Some items which need work:
- Tweak properties to address the issues raised above.
- Start fetching attachments as well.
- Support further syncs. Currently, a big sync is done once, and
there’s no way to tell
sdto sync new changes since last time, if any. This will probably lead to rewriting how fetching is currently done, which is: discover all bugs, then fetch all comments and all history items, for all of them. Properties likelast_change_timewill probably be of some help here. - Have a look at what happens with other bugzilla instances, like Gnome’s.